Originally published by Sanuwar Rashid on July 22, 2024
Beyond Prompts: The Logic Behind Intelligent Agents
To build autonomous agents that can reason, retrieve, and act — especially using low-code tools like n8n, Flowise, or LangFlow — prompts alone won’t take you far. You need the logic behind the prompts. This exploration goes deeper into how agentic workflows work, how data is broken down and fed to the brain of AI, and why RAG (Retrieval-Augmented Generation) is changing the game.
Three Ways to Give LLMs Additional Knowledge
We often want to give additional knowledge to large language models (LLMs). There are a few ways to do that:
- In-context learning – feeding information directly into the prompt window
- RAG pipelines – retrieving relevant information from external sources like vector databases
- Fine-tuning – retraining the model with new data, which is expensive and rigid
The Context Window Problem
Let’s say you want to teach an LLM something new. You can pass context (like a document) into the prompt, and the LLM might “learn” it momentarily. But context window has limits. If you try to jam in a thousand PDFs, you’ll hit the ceiling — the token limit. And when you overload the context window, the LLM might not even follow what you’re trying to say. Sounds like drifting? Yes, exactly.
What is a context window, by the way? It’s the amount of “space” the model has to remember things while answering your query. Too much information, and it starts forgetting the beginning before it reaches the end.
RAG: The Smart Assistant Approach
In-context learning is like showing an LLM a sticky note just before it answers a question — it can read what’s on the note, but once the space runs out, it can’t remember more. Retrieval-Augmented Generation (RAG), on the other hand, is like giving the model a smart assistant who can flip through a library of sticky notes and hand it only the most relevant one each time you ask something. Instead of overloading the model with all your data upfront, RAG dynamically fetches just the pieces that matter, right when they’re needed.
Ever tried a Custom GPT inside ChatGPT? You can upload your resume, and the GPT remembers it across sessions. You can ask it to analyze job postings based on your profile. This persistent memory works not because the GPT memorized you — but because it retrieves the right context from the uploaded document every time you ask.
If you’ve ever used a Custom GPT that remembers your uploaded resume or project notes across chats — you’ve used RAG. It doesn’t memorize your files; it fetches relevant content every time you ask.
RAG vs Fine-Tuning: The Key Differences
RAG is very different from fine-tuning, which actually rewires the model’s internal weights to “bake in” new knowledge permanently. Fine-tuning is slower, more expensive, and requires retraining the model whenever your knowledge base changes. RAG is faster, cheaper, and more flexible — it acts like a just-in-time memory layer, not a brain transplant.
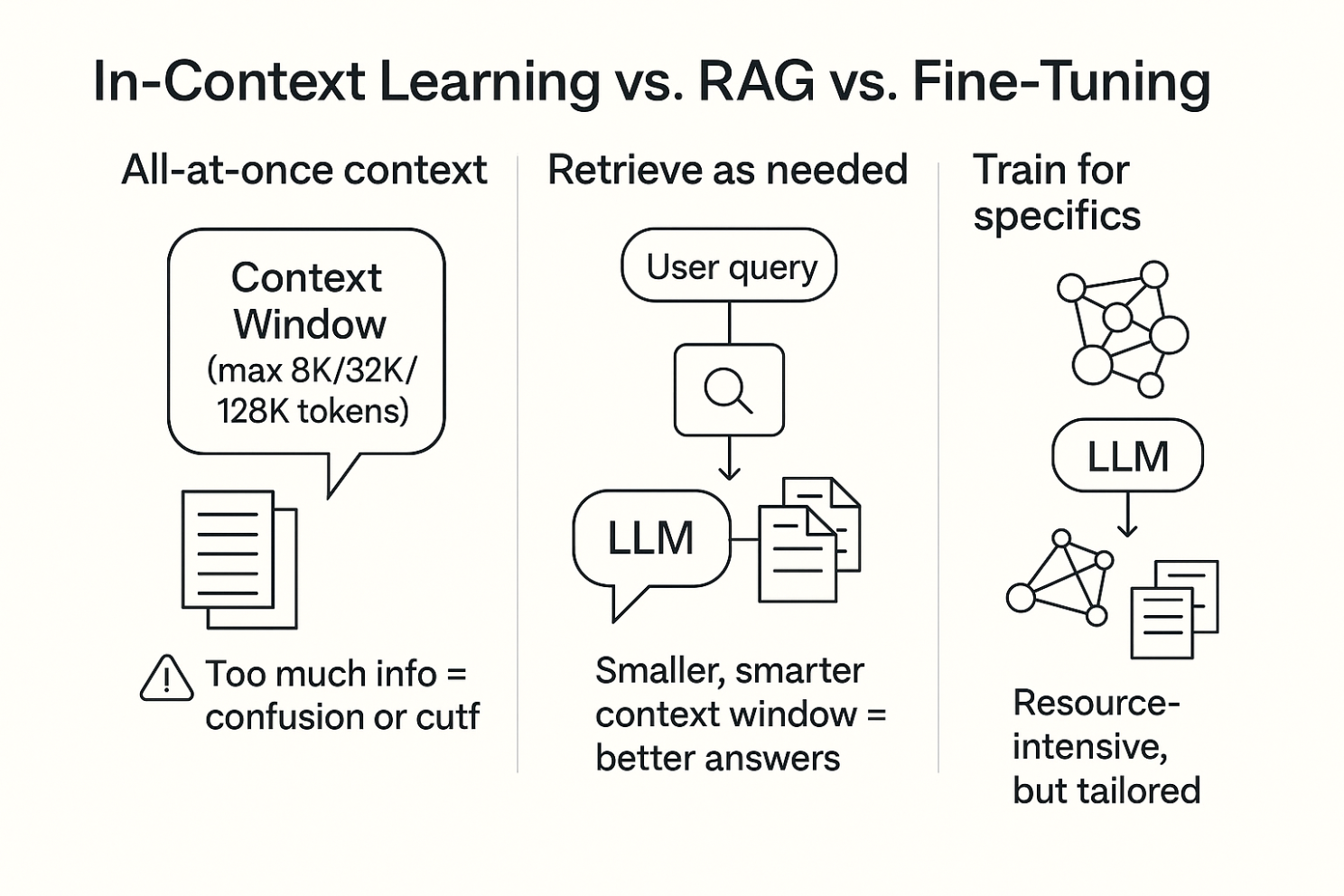 A 3-column comparison showing In-Context Learning (“All-at-once context,” limited by token window), RAG (“Retrieve as needed,” pulls relevant docs per query), and Fine-Tuning (“Train for specifics,” resource-intensive but tailored).
A 3-column comparison showing In-Context Learning (“All-at-once context,” limited by token window), RAG (“Retrieve as needed,” pulls relevant docs per query), and Fine-Tuning (“Train for specifics,” resource-intensive but tailored).
How RAG Works Behind the Scenes
Here’s how that happens behind the scene:
An embedding model takes your documents and converts them into numerical representations — vectors. These vectors are not stored on a literal 3D chessboard, but in a high-dimensional space (think 768D or 1536D), where similar meanings end up closer together.
These vectors are stored in a vector database. When you ask a question that the LLM doesn’t know, a retriever fetches similar chunks from the vector database based on your query. The result? Relevant pieces of text are fed back into the LLM’s context window so it can answer your question like it knew the answer all along.
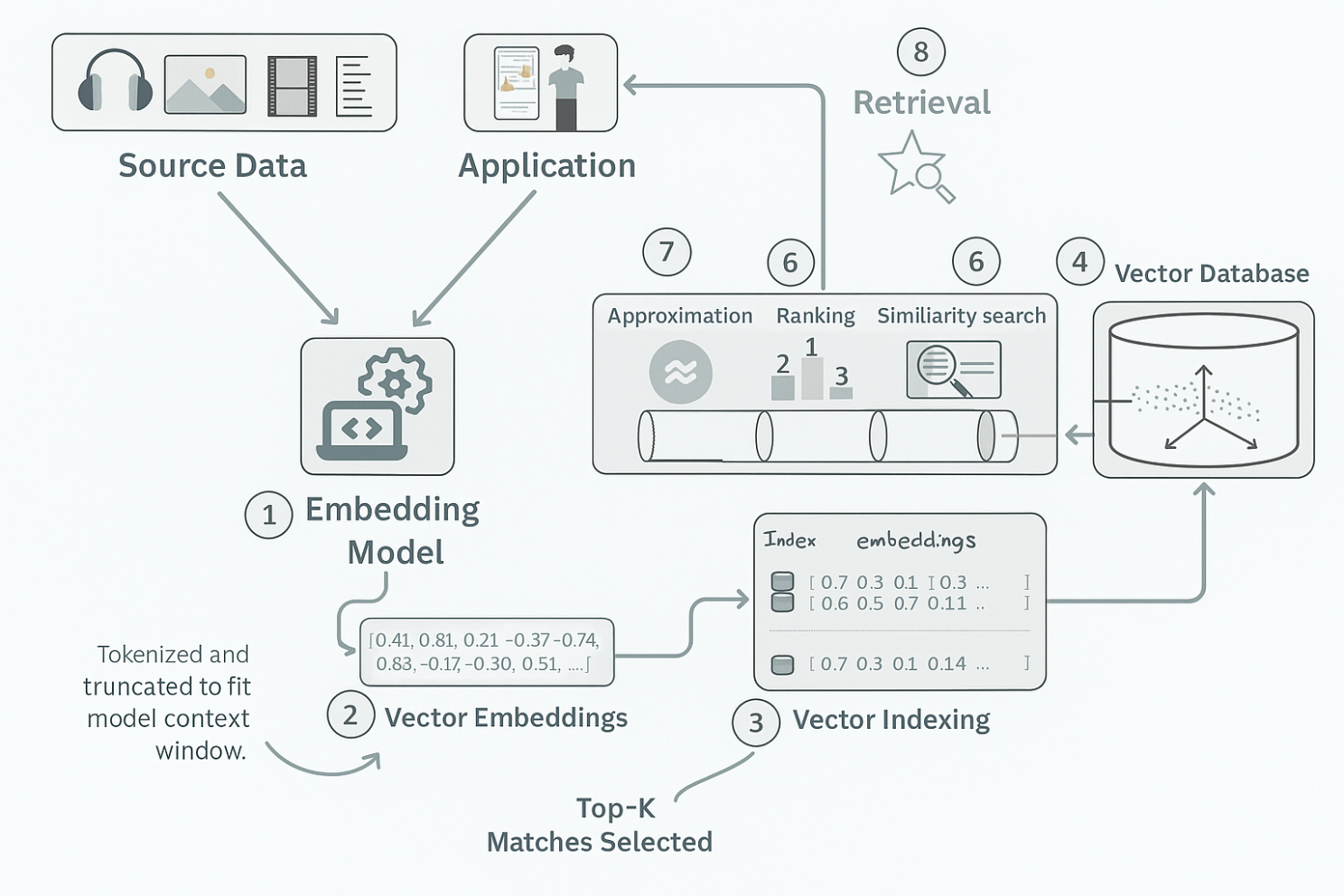 A diagram showing how source data is embedded into vectors, indexed, stored in a vector database, and retrieved based on similarity scoring to return top-k relevant results to the application.
A diagram showing how source data is embedded into vectors, indexed, stored in a vector database, and retrieved based on similarity scoring to return top-k relevant results to the application.
The Chunking and Retrieval Process
Documents are broken into chunks. Each chunk is usually a few hundred tokens (words and characters). Say your chunk size is 500 — that means each chunk has up to 500 tokens. When a query comes in, the system retrieves Top-K chunks — say, the top 4 most relevant chunks based on similarity. If Top-K = 4 and chunk size = 500, you’re feeding about 2000 tokens of relevant data back into the LLM.
So, when the user asks a question → the retriever does a similarity search → finds top K relevant chunks → sends those chunks into the LLM → the LLM answers based on that injected context.
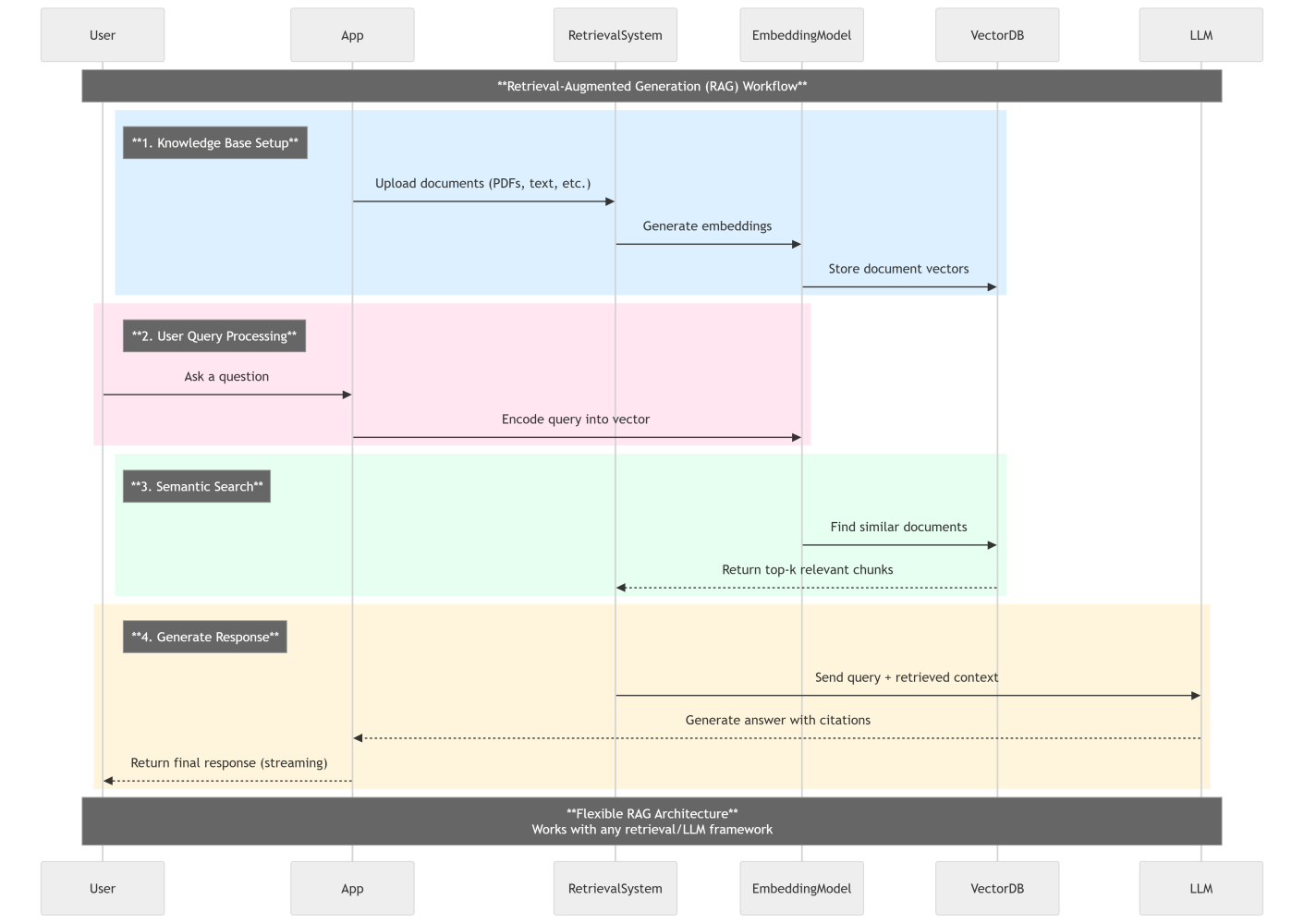 This diagram breaks down a complete RAG pipeline: from setting up a knowledge base to generating final answers with citations. It showcases how vector search, embeddings, and large language models (LLMs) come together to deliver context-aware, efficient responses — a foundation for many GenAI applications today.
This diagram breaks down a complete RAG pipeline: from setting up a knowledge base to generating final answers with citations. It showcases how vector search, embeddings, and large language models (LLMs) come together to deliver context-aware, efficient responses — a foundation for many GenAI applications today.
The Complete RAG Pipeline
The possibility of RAG starts here! And with smart orchestration, agents can do even more — retrieving knowledge, making decisions, and even executing actions based on retrieved context.
Key Takeaways
In sum, the magic isn’t in just feeding data. It’s in embedding, chunking, retrieving, and injecting the right information at the right time. That’s how we move from raw text to smart actions — one chunk at a time.
The RAG approach enables:
- Dynamic knowledge access without token limits
- Cost-effective updates to knowledge bases
- Contextual relevance through similarity search
- Scalable intelligence for autonomous agents
Related Topics
This article connects to broader themes in AI engineering, including vector search optimization, embedding model selection, and agentic workflow design.